
RESEARCH ON SEMANTIC SEGMENTATION OF GREENHOUSE ROAD IMAGE
温室大棚道路图像的语义分割研究
DOI : https://doi.org/10.35633/inmateh-71-65
Authors
(*) Corresponding authors:
Abstract
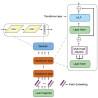
To realize the automatic driving of agricultural machinery in the greenhouse, this paper uses image acquisition equipment to collect road images in the greenhouse and makes data sets, builds SETR (SEgmentation TRansformer) model based on Transformer framework and DeepLabv3+ model based on convolution neural network for semantic segmentation of road images in the greenhouse, and verifies the semantic segmentation ability of the two models to road images in the greenhouse. Several groups of training periods are set as observation points to observe the semantic segmentation effect of the two models on the greenhouse road image, and the test set which has not been trained by the model is used as the prediction object to verify the performance of the two models on the semantic segmentation of greenhouse road image. The SETR model reached 94.64% PA (Pixel Accuracy) on the greenhouse road data set, and 82.72% mIoU (Mean Intersection over Union), DeepLabv3+ model reached 90.80% PA and 72.35% mIoU on the greenhouse road data set. Both models have excellent performance in semantic segmentation of greenhouse road images, and the performance of SETR model is slightly better than that of DeepLabv3+ model. The semantic segmentation performance of the two models for greenhouse road images can meet the needs of actual deployment.
Abstract in Chinese
